What is pyspark-ai?
PySpark-AI is a Python wrapper that leverages generative language models to simplify PySpark code generation. By accepting instructions in English, it combines the power of Apache Spark with models like GPT-4 and GPT-3.5. PySpark-AI enables data input through various methods and provides functions for creating DataFrames, transforming and plotting data, working with UDFs, explaining queries, and committing data. With a focus on data rather than coding, PySpark-AI has the potential to streamline PySpark workflows, enhance efficiency, and simplify data processing for data scientists.
Requirements and setup
We need python 3.8 or above and pip installed on the system. We also need OPENAI_API_KEY key for GPT-4, GPT-3.5, etc. We can get the API keys from OpenAI. You will need the following packages installed on your system:
pip install pyspark-ai pyspark plotly
You can also checkout pyspark-ai github repo for more details.
You will also need JAVA 8 or above installed on your system.
If you want to use google search query to get the data, you need GOOGLE_API_KEY for that. We can create the GOOGLE_API_KEY and GOOGLE_CSE_ID (if they aren't already created) from https://developers.google.com/custom-search/v1/introduction and https://cse.google.com/cse/create/new, respectively.
Usage
input data
There are several ways to input the data to the pyspark-ai, like google search query, url, standard input to pyspark, etc.
from langchain.chat_models import ChatOpenAIfrom pyspark_ai import SparkAI
llm = ChatOpenAI(model_name='gpt-4', temperature=0) # If 'gpt-4' is unavailable, use 'gpt-3.5-turbo'
spark_ai = SparkAI(verbose=True)# verbose True to see what is happening behind the scenes.
spark_ai = SparkAI(llm=llm, verbose=True) # we can specify the language model to use.
spark_ai.activate()
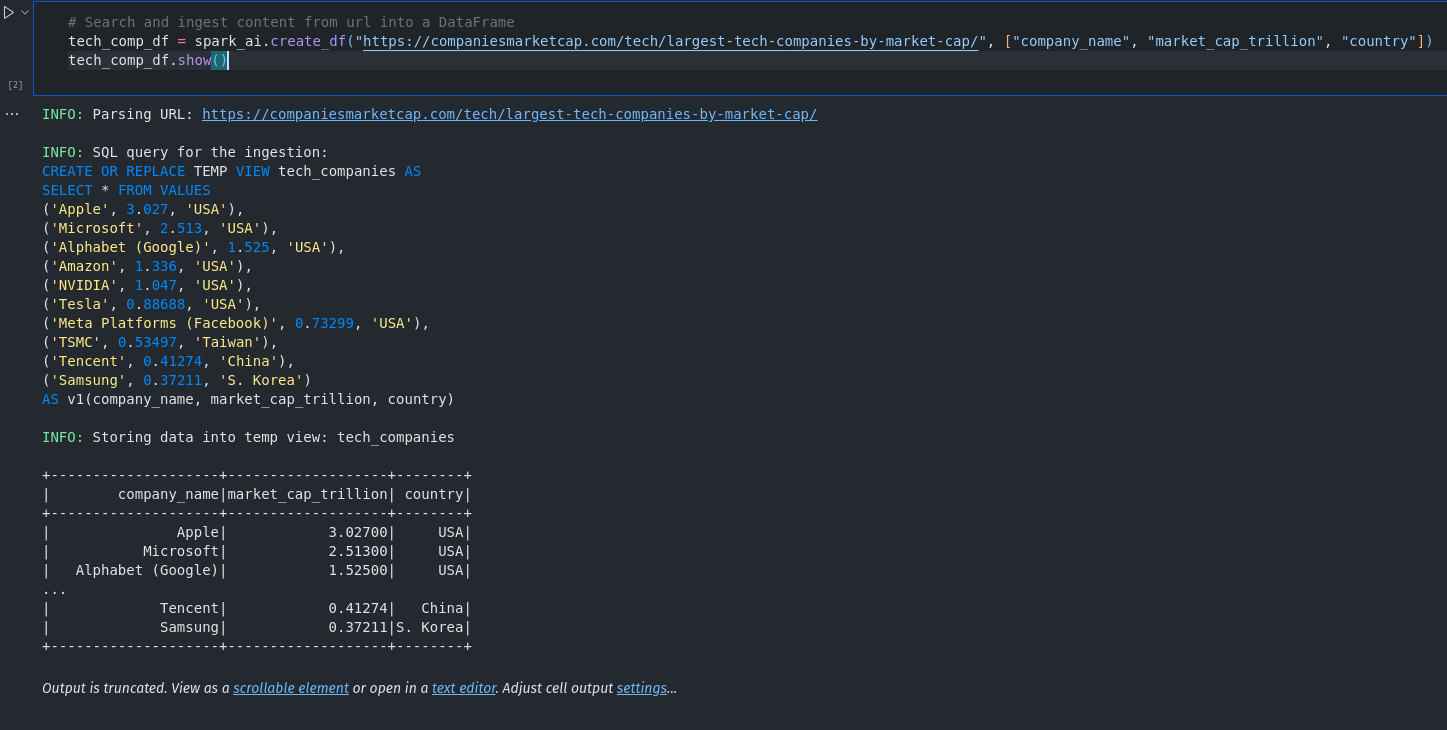
tech_comp_df = spark_ai.create_df("https://companiesmarketcap.com/tech/largest-tech-companies-by-market-cap/")
# By default it will create a dataframe with significant columns. We can specify the column names as well.
tech_comp_df = spark_ai.create_df("https://companiesmarketcap.com/tech/largest-tech-companies-by-market-cap/", ["company_name", "market_cap_trillion", "country"])
# We can also use google search query to get the data. We need GOOGLE_API_KEY and GOOGLE_CSE_ID for that.
tech_comp_df = spark_ai.create_df("largest tech companies by market cap", ["company_name", "market_cap_trillion", "country"])
# we can also use standard input to get the data.
import pyspark
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName("tech_comp").getOrCreate()
manual_df = spark.read.csv("1000 Sales Records.csv", header=True, inferSchema=True)
# 1000 Sales Records.csv is a local file
# similarly we can use other data sources as well like postgres, hive, etc.
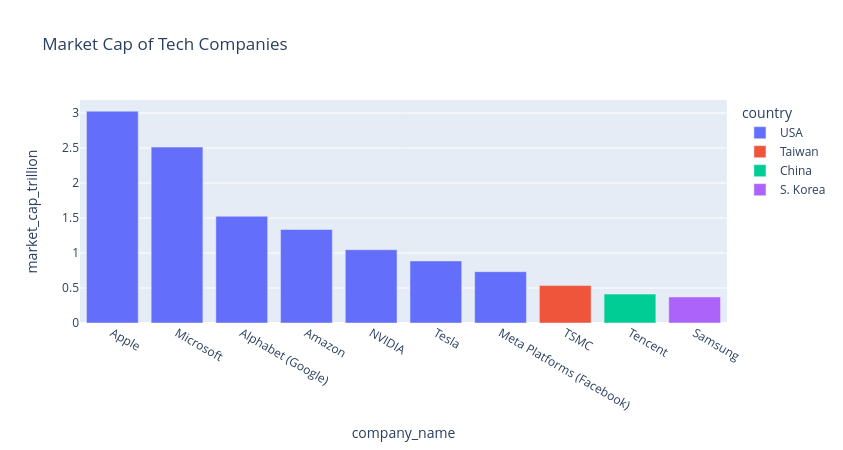
plot
We can use the plot function to plot the data. It will do its best to find the best plot type and columns for the data. We can just give instructions using natural English, and it will do the rest. For Example:
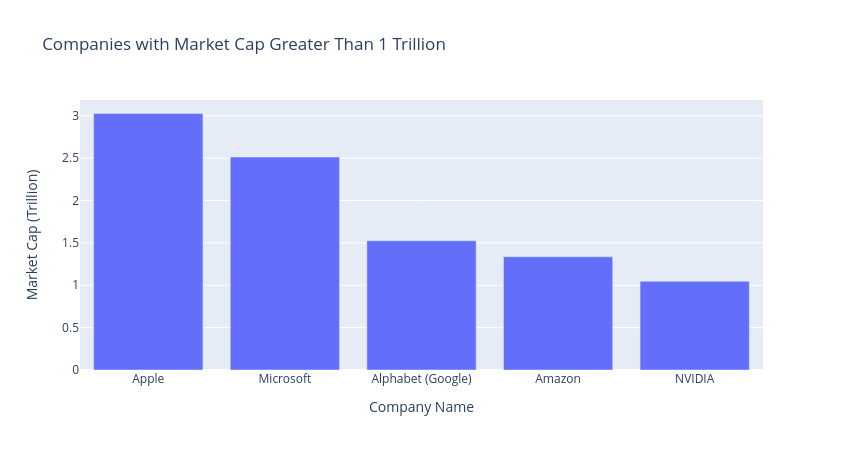
tech_comp_df.ai.plot()tech_comp_df.ai.plot("company with market cap greater than 1 trillion")
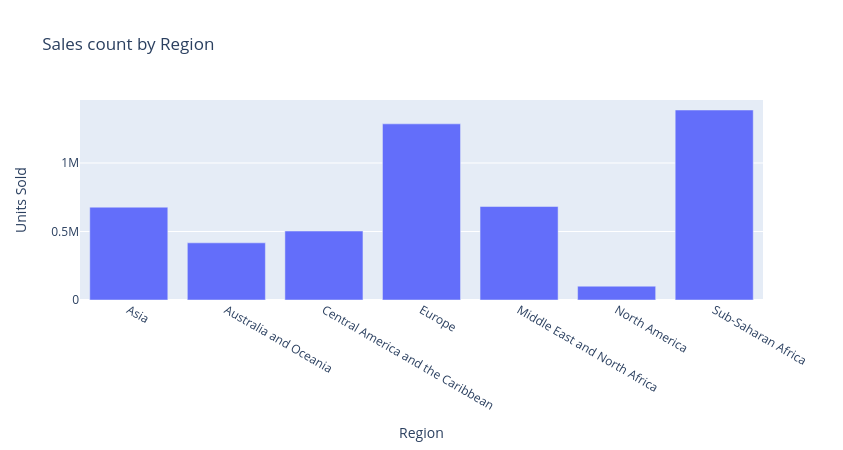
manual_df.ai.plot("Sales count by Region")
transform
We can use the transform function to transform the data. Again, we can just give instructions in natural English, and it will do the rest. For Example:
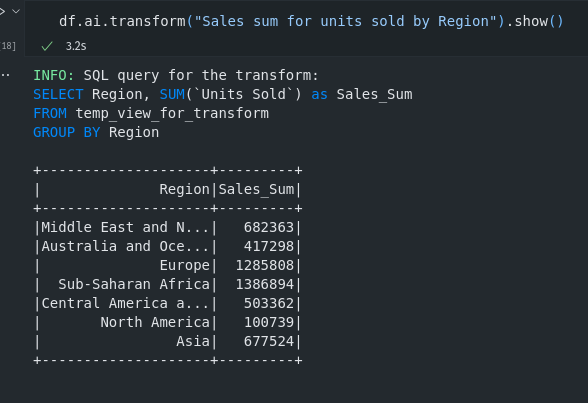
manual_df.ai.transform("Sales sum for units sold by Region").show()manual_df.ai.transform("Sum of all the orders served in North America").show()
# similarly we can use tech_comp_df
UDFs
UDFs are user defined functions. We can use UDFs to do specific transformation and use it inside queries.
@spark_ai.udfdef diff_bw_ship_date_and_order_date(ship_date, order_date) -> int:
"""Order date and ship date are date strings formatted as MM/DD/YYYY, calculate the difference in days"""
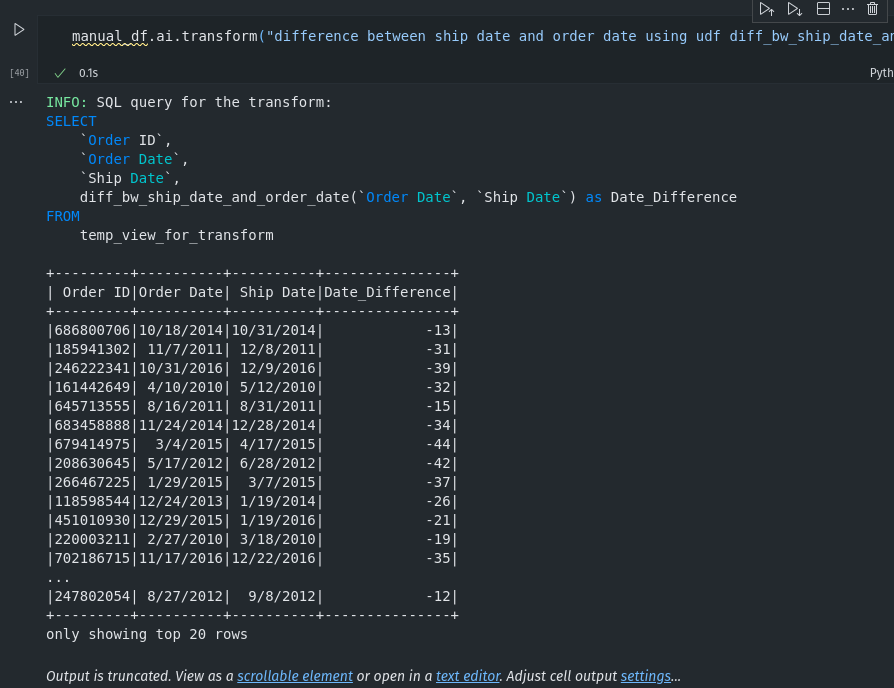
# providing more description increases the chance of getting the correct query.# now we only need to registed this udf
spark.udf.register("diff_bw_ship_date_and_order_date", diff_bw_ship_date_and_order_date)
manual_df.createOrReplaceTempView("manualDF")
# use of UDF
manual_df.ai.transform("difference between ship date and order date using udf diff_bw_ship_date_and_order_date ").show()
explain
We can use the explain function to explain the query. It will do its best to explain the query.
manual_df.ai.explain()# output
'In summary, this dataframe is retrieving all columns from the CSV file. The columns include Region, Country, Item Type, Sales Channel, Order Priority, Order Date, Order ID, Ship Date, Units Sold, Unit Price, Unit Cost, Total Revenue, Total Cost, and Total Profit.'
verify
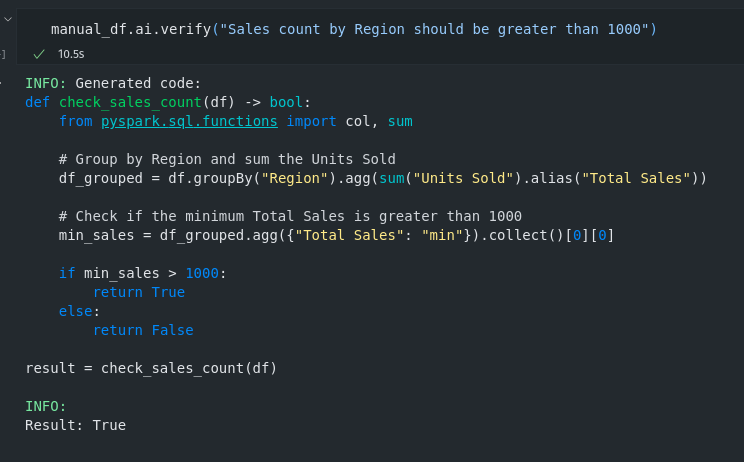
We can also use verify functions to put validation in place.
manual_df.ai.verify("Sales count by Region should be greater than 1000")
# or
tech_comp_df.ai.verify("name of companies should be unique")
output
We can use the commit function to save the data in persistent storage.
spark_ai.commit()
All this code is available in the following downloadable python notebook pyspark-ai.iypnb
conclusion
pyspark-ai simplifies pyspark code generation, helping data scientists focus on the data rather than the code. It has a lot of potential, and we can increase its efficiency by giving it detailed descriptions and instructions, in natural English. This tool is quite new; it will be interesting to see how it evolves in the future.